Что такое поток?
Большинство из вас должно быть уже знают что такое потоки, но тем не менее, здесь приведено небольшое объяснение для тех, кто впервые сталкивается с этой концепцией.
Поток это последовательность инструкций, которая обрабатывается параллельно другим потокам (т.е. параллельно другим инструкциям). Каждая программа состоит как минимум из одного потока: главного потока, который запускает функцию main(). Программы, использующие только один поток, называются однопоточными, но если вы добавите в неё один или несколько потоков, то она уже будет многопоточной.
Короче говоря, потоки это способ делать несколько вещей одновременно. Это может быть полезно, например, при отображении анимации и реагировании на пользовательский ввод, во время загрузки изображений и звуков. Потоки также широко применяются в сетевом программировании, пока данные загружаются в одном потоке, другой может заниматься обновлением и отображением приложения.
Потоки SFML или std::thread?
В своей последней версии (2011) стандартная библиотека С++ предоставила набор классов для работы с потоками. В то время когда была написана SFML, ещё не существовало стандарта С++11 и не было стандартного пути для создания потоков. На момент релиза SFML 2.0, большинство компиляторов ещё не поддерживало новый стандарт С++11.
Если вы работаете с компилятором поддерживающим новый стандарт и его заголовок <thread>, то забудьте про класс SFML и используйте его — это будет намного лучше. Если же вы работаете с компилятором не поддерживающим новый стандарт C++11 или планируете распространять свой код и сделать его полностью переносимым, тогда использование потоков, реализованных через SFML, будет хорошим решением.
Создание потока с помощью SFML
Хватит болтать, давайте уже посмотрим на код. Класс для реализации потока в SFML называется sf::Thread. Вот пример того, как его можно использовать:
#include <SFML/System.hpp>
#include <iostream>
void func()
{
// эта функция запускается после вызова thread.launch()
for (int i = 0; i < 10; ++i)
std::cout << "I'm thread number one" << std::endl;
}
int main()
{
// создаём поток с функцией func() в качестве входной точки
sf::Thread thread(&func);
// запускаем поток
thread.launch();
// главный поток при этом продолжает работу...
for (int i = 0; i < 10; ++i)
std::cout << "I'm the main thread" << std::endl;
return 0;
}
В этом коде функции main() и func() обрабатываются параллельно после вызова thread.launch(). В результате этого текст из обоих функций должен смешаться в консоли.
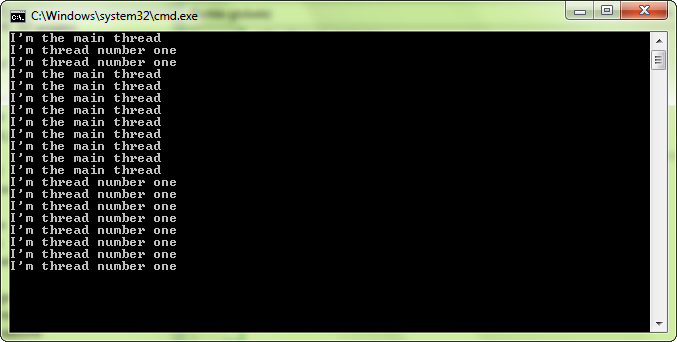
Входная точка для потока, т.е. функция, которую запускают в отдельном потоке, должна пройти через конструктор sf::Thread. sf::Thread может принимать различные точки входа: методы класса и функции ими не являющиеся, функции с аргументами и без них, функторы и т.п. Пример выше показывает как использовать функцию, не являющуюся методом класса, вот ещё несколько других примеров.
— Функция не метод класса с одним аргументом:
void func(int x)
{
}
sf::Thread thread(&func, 5);
— Метод класса:
class MyClass
{
public:
void func()
{
}
};
MyClass object;
sf::Thread thread(&MyClass::func, &object);
— Функтор (функция-объект):
struct MyFunctor
{
void operator()()
{
}
};
sf::Thread thread(MyFunctor());
Этот последний пример, с использованием функтора, один из самых действенных, поскольку можно взять функтор любого вида, и, тем самым, сделать класс sf::Thread совместимым с функциями, виды которых напрямую не поддерживаются. Это свойство особенно интересно с учётом поддержки в C++11 лямбда-выражений и std::bind.
// с лямбда-выражением
sf::Thread thread([](){
std::cout << "I am in thread!" << std::endl;
});
// c std::bind void func(std::string, int, double) { } sf::Thread thread(std::bind(&func, "hello", 24, 0.5));
Если вы хотите использовать sf::Thread внутри класса, то не забудьте что sf::Thread не имеет конструктора по умолчанию. Поэтому вы должны провести правильную инициализацию в конструкторе вашего класса.
class ClassWithThread
{
public:
ClassWithThread()
: m_thread(&ClassWithThread::f, this)
{
}
private:
void f()
{
...
}
sf::Thread m_thread;
};
Если вам нужно создать свой экземпляр sf::Thread после создания вашего объекта, вы можете так же задержать его создание с помощью размещения этого экземпляра в куче используя оператор new. (Если честно, то я не уверен что абсолютно правильно перевёл это предложение.. поэтому предоставляю оригинал: If you really need to construct your sf::Thread instance after the construction of the owner object, you can also delay its construction by allocating it on the heap with new.)
Запуск потока
После создания экземпляра sf::Thread, его необходимо запустить с помощью функции launch().
sf::Thread thread(&func); thread.launch();
launch() вызывает функцию, которую вы передали в конструктор нового потока, и тут же заканчивает свою работу, что бы вызывающий поток мог продолжить свою работу.
Остановка потока
Поток автоматически останавливается после того, как функция, вызванная в этом потоке, завершает свою работу. Если вы хотите подождать завершения потока в потоке из которого он был создан, то можно воспользоваться функцией wait().
sf::Thread thread(&func); // запуск потока thread.launch(); ... // блокирование выполнения, пока поток не завершит работу thread.wait();
Функция wait() неявно вызывается деструктором sf::Thread, так что поток не может остаться в живых (и выйти их под контроля). Имейте это ввиду когда будите управлять вашими потоками.
Пауза для потока
sf::Thread не имеет функции которая могла бы позволить одному потоку приостановить работу другого, единственный способ это осуществить заключается в том, что бы поток который хотим приостановить, приостанавливать изнутри. Это можно сделать используя функцию sf::sleep() :
void func()
{
...
sf::sleep(sf::milliseconds(10));
...
}
sf::sleep() принимает один аргумент — время сна. Подробнее про время можно почитать в уроке «Обработка времени».
Обратите внимание на то, что таким способом вы можете усыпить любой поток, даже главный.
sf::sleep() это наиболее эффективный способ усыпления потока: пока поток спит, он не нагружает процессор. Пауза основана на активном ожидании, в то время как пустой цикл while потреблял бы 100% CPU, не делая при этом ничего. Однако, имейте ввиду, что продолжительность сна является лишь примерной и в зависимости от операционной системы она будет более или менее точной. Не стоит полагаться на эту функцию для очень точного расчёта времени.
Защита общих данных
Все потоки программы делят общую память и потому имеют доступ ко всем переменным программы. Это очень удобно, но в тоже время и опасно: поскольку потоки запущенны параллельно, то переменные или функции могут быть использованы одновременно разными потоками в одно и тоже время. И если операция не потокобезопасная (thread-safe), то результат не определён (т.е. он может привести к сбою или повреждению данных).
Существуют некоторые программные конструкции для защиты общих данных и создания потокобезопасного кода, они называются примитивы синхронизации (synchronization primitives). Среди них распространены мьютексы, семафоры, условия ожидания и спин-блокировки. Все они варианты одной и той же концепции: они защищают часть кода, разрешая доступ одному конкретному потоку, но запрещая при этом для всех остальных.
Самый основной (и часто используемый) примитив — мьютекс. Мьютекс расшифровывается как «взаимное исключение» (MUTual EXclusion): он разрешает только одному потоку в данный момент времени доступ к коду, который его окружает. Давайте посмотрим, как они могут навести порядок в приведённом выше примере:
#include <SFML/System.hpp>
#include <iostream>
sf::Mutex mutex;
void func()
{
mutex.lock();
for (int i = 0; i < 10; ++i)
std::cout << "I'm thread number one" << std::endl;
mutex.unlock();
}
int main()
{
sf::Thread thread(&func);
thread.launch();
mutex.lock();
for (int i = 0; i < 10; ++i)
std::cout << "I'm the main thread" << std::endl;
mutex.unlock();
return 0;
}
Этот код использует общий ресурс (std::cout), и, как мы видели, это производит не желательные последствия — всё смешалось в консоли. Что бы убедиться что текстовые сообщения не смешались произвольным образом, мы защитим соответствующие участки кода с помощью мьютексов. Первый поток, который достигает своей функции mutex.lock(), успешно блокирует мьютекс, при этом сразу же получая доступ к коду который выводит текст сообщений. Когда другой поток достигает mutex.lock(), то мьютекс всё ещё заблокирован и, таким образом, этот поток засыпает (так же с помощью sf::sleep(), потому процессор при этом не нагружается спящим потоком). Когда первый поток наконец разблокирует мьютекс, второй поток просыпается, блокирует мьютекс и выводит текст. Таким образом строки появляются в консоли без смешивания.
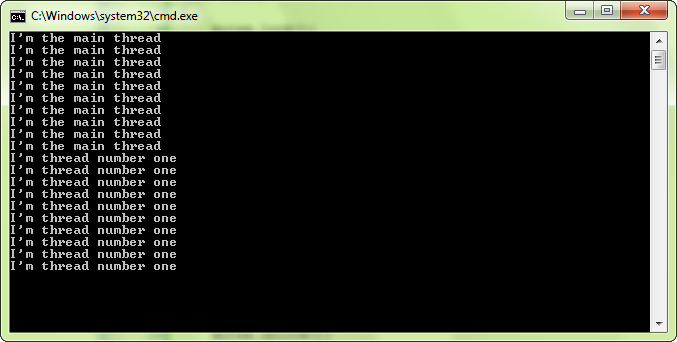 Мьютексы не являются единственными примитивами которые вы можете использовать для защиты общих данных, но их обычно бывает достаточно для большинства случаев.
Мьютексы не являются единственными примитивами которые вы можете использовать для защиты общих данных, но их обычно бывает достаточно для большинства случаев.
Защита мьютексов
Не волнуйтесь: мьютексы всегда потокобезопасные, нет необходимости защищать их. Но они не исключительно-безопасные (exception-safe)! Что произойдёт, если в то время пока заблокирован мьютекс, вызовется исключение? Он никогда не получит шанс на разблокирование и останется заблокированным навсегда. Все потоки которые будут пытаться вызвать блокировку, будут заблокированы навечно; всё ваше приложение может полностью зависнуть. Думаю вы понимаете на сколько это плохо.
Что бы убедиться, что мьютексы всегда разблокированы в том участке кода, где возможно срабатывание исключений, SFML предоставляет RAII класс что бы обернуть их: sf::Lock. Этот класс запирает мьютекс в своём конструкторе и отпирает его в деструкторе. Просто и эффективно.
sf::Mutex mutex;
void func()
{
sf::Lock lock(mutex); // mutex.lock()
functionThatMightThrowAnException(); // mutex.unlock() если эта функция выбрасывает исключение
} // mutex.unlock()
Обратите внимание на то, что sf::Lock может быть полезным с функциями имеющими несколько операторов возврата.
sf::Mutex mutex;
bool func()
{
sf::Lock lock(mutex); // mutex.lock()
if (!image1.loadFromFile("..."))
return false; // mutex.unlock()
if (!image2.loadFromFile("..."))
return false; // mutex.unlock()
if (!image3.loadFromFile("..."))
return false; // mutex.unlock()
return true;
} // mutex.unlock()
Типичные ошибки
Одну вещь программисты часто упускают из виду, заключается она в том, что поток не может жить без своего экземпляра sf::Thread. Следующий код часто встречается на форумах:
void startThread()
{
sf::Thread thread(&funcToRunInThread);
thread.launch();
}
int main()
{
startThread();
// ...
return 0;
}
Программисты, которые пишут такой код, ожидают что функция startThread() запустит поток, живущий сам по себе. Но происходит другое: функция, запускаемая в потоке означает блокировку для главного потока.
Так в чём же причина? Экземпляр sf::Thread является локальным для функции startThread() и поэтому, сразу же уничтожается при её завершении. Деструктор sf::Thread срабатывает и вызывает задержку wait(), как это было показано выше, в результате этого, главный поток оказывается заблокированным и ожидает завершения функции, запускаемой в потоке, вместо того что бы продолжить работу параллельно ей.
И так, помните: вы сами должны управлять вашими экземплярами sf::Thread так, чтобы они существовали так долго, как работает функция, запускаемая в потоке.
Крутая статья!